Hello there 👋 ! We are now at 4500+ subscribers 💪 💪. Thank you for your love and support ❤️ ❤️. I am enjoying it, I hope you are enjoying it too! I have been away for some time building a community with ThreeHundredDaysOfCode.
Before we go into the design of the Rate Limiter, let us first go through some of the common terminologies which will help us develop a better conceptual understanding of the problem statement.
Rate Limiting
Rate Limiting is a network-based strategy that is used to control the rate of requests that are being sent to a server from a client or a collection of clients. It is typically used to prevent DoS attacks and limit web scraping. Typically, rate-limiting is a client-side response.
Throttling
Throttling is a server-side response where feedback is provided to the caller indicating that there are too many requests. The objective is similar to Rate Limiting. Implementing, it on the server makes the overall architecture scalable and resilient to distributed denial of service attacks.
Noisy Neighbor Problem
Typical web services are built in a multi-tenant model. This means that the underlying resources such as the Network, Disk, Database, etc. are shared between multiple clients. In such an architecture one of the tenants can hog the resources such as network bandwidth by triggering several queries to the system. It leads to a lack of resources for other tenants. We call this problem the Noisy Neighbor Problem. (link)
Problem Statement
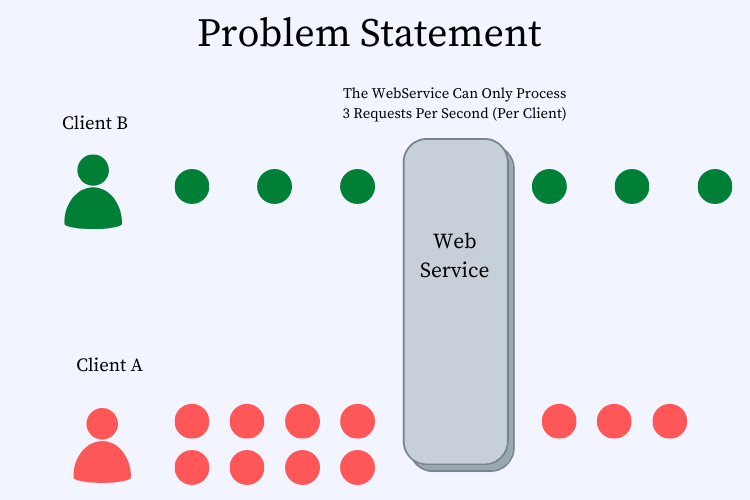
Let us say that you are building a web application — a video streaming platform and the application becomes really popular i.e. it starts to get a lot of traffic. Imagine, a malicious user who launches an attack on the application and starts to bombard the server with hundreds of thousands of requests. In that scenario, the application may struggle to respond to each of the incoming requests. Let us look at figure XXX. to better understand this use case. In this figure, we have made the assumption that the WebService can handle only 3 requests per second per client. Client B sends 3 requests and the Web Server handles them properly. However, client A (being a rogue client) sends 8 requests. The Web Server will need to allocate more resources (including network bandwidth, CPU, disk space, etc.) to client A than to client B. In this scenario, client A acts as a noisy neighbor, and this problem is often referred to as the Noisy Neighbor problem. The ideal scenario would be that the webserver should allocate resources in a balanced manner to both clients.
Figure 1. Depicts the “Noisy Neighbor” problem wherein client A triggers more requests to the web server than what it can handle. This situation then leads client A to hog resources that should have been allocated to client B. A rate-limiting solution focuses on addressing this problem.
Questions
Before we begin to design the system, let us first think through some of the questions that might need clarification.
Clarification-I: Can we not design the system to auto-scale? Then we need not worry about rate-limiting as the system should increase its capacity as the number of requests increases.
Answer: It is definitely a valid question to ask. The only problem with such a design pattern is that auto-scaling requires time. Spinning up a new microservice can typically take a few 100 ms to a few seconds and this can cause the user to have degraded performance experience.
Clarification-II: Can we simply not use a load-balancer?
Answer: The most common approach is to use load-balancers and they do suffice to an extent. Some of the downsides of using a load-balancer is that they typically aren’t aware of the application semantics i.e. they do not have an understanding of which traffic to let through. Let us take two requests in a video application like YouTube. One of the requests may be to load a short video while the other may be to load 100 of large videos. The second request is costly and may result in a large number of resources being used. A load-balancer may not be able to deduce this and lead to poor balancing of resources across several requests.
Clarification-III: Why do we need a distributed solution?
Answer: It is a good question. Web services are typically composed of several redundancies. If we design a single-node solution the problem tends to be that we end up being exposed to distributed attacks. For eg. a malicious client may distribute its requests from different IP addresses and may result in the system never throttling its requests. A distributed solution will be able to identify the client by figuring out the sum total of all the resources expended by a malicious client. A distributed solution, therefore, tends to be much more stable and accurate.
In the next section, let us go through the functional and nonfunctional requirements for the problem.
Functional Requirement
Let us first go through the functional requirements for the problem.
allowRequest(request) - The requirement here is simple. The server should implement a method that given a request should decide whether the request can go through or not and return a boolean.
Non-Functional Requirement
Let us now go through the non-functional requirements for the problem.
Low Latency (make decision as soon as possible) - The system design should have low-latency. It means that the system making the call should be able to make the call as fast as possible and shouldn’t have a high perceived latency on the client.
Accurate (as accurate as we can get) - The system design should be as accurate as possible. Even if the malicious client sends requests from many different sources using different obfuscation techniques, the server should be able to deduce and prevent attacks.
Scalable (supports an arbitrarily large number of hosts in the cluster) - The system design should be scalable. We should be able to rate the limit at 1 server to 100k servers with a linear increase in expended resources. The system should not cripple under extreme load.
Start With A First-Principles Approach
To begin solving the problem, we will start with a single-node solution and then think about making it a distributed solution.
Solution#1: Single Server Solution
The most important components of the design are as follows:
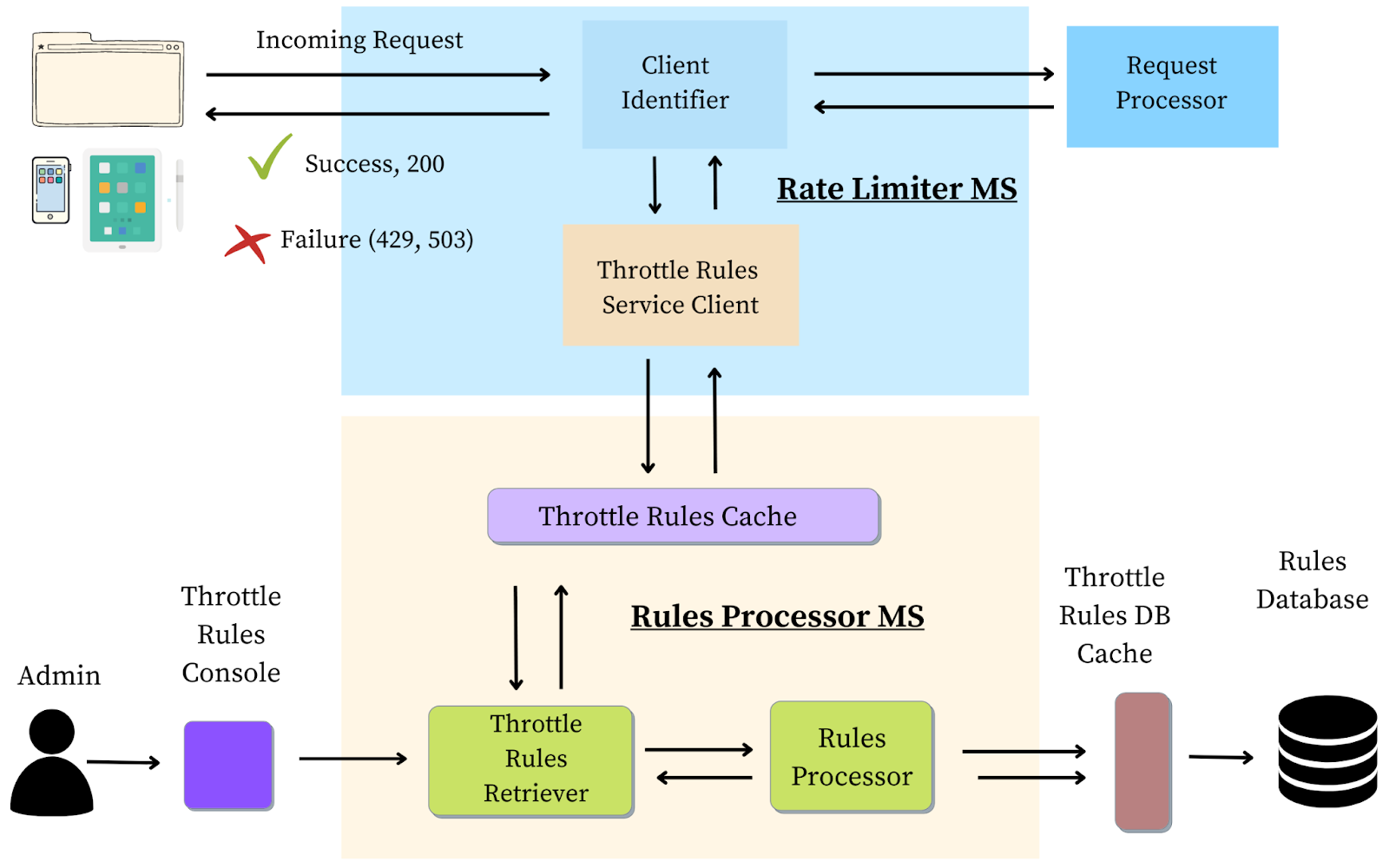
Client Identifier: The Client Identifier identifies the client based on the session credentials, client IP, or browser signatures. It ensures that each request is correctly attributed to the requesting client.
Throttle Rules Service Client: A client to send requests to the Throttle Rules Microservice.
Throttle Rules Retriever: A module that gets the set of applicable rules from the rules processing engine.
Rules Processor: The core engine that retrieves all the rules from secondary storage (such as a Database) and decides whether the request should be processed or not.
Rules Database: The rules database contains a list of all the rules that govern how requests should be throttled.
Rule Console: A console engine that the administrator can use to create, read, update, or delete rules.
Workflow
Let us go through the workflow with which the request is processed using the aforementioned modules. We have divided this into the following seven steps:
Step-I: The client makes a request to the Rate Limiter MS, which acts as the frontend to the Request Processor service.
Step-II: The client identifier assigns a unique id to the request based on the client from which the request emanates from.
Step-III: The request is then passed to the Throttle Rules Service client that makes a call to the Rules Processor module to make an accept/reject decision.
Step-IV: The Rules Processor uses the Rules Retriever to get the set of rules from the Rules Cache (backed by a Rules Database).
Step-V: The Rules Processor sends a response back to the Throttle Rules Service Client.
Step-VI: If the request is valid, and within the bounds of the service agreement, the request is accepted and sent to the Request Processor.
Step-VII: If the request cannot be processed a 429, or 503 error is sent back to the client to try the request again later.
Rate Limiter Algorithms
In this section let us discuss four rate-limiting algorithms that are good to discuss with the interviewer. To read more visit this link.
Token Bucket: The token bucket algorithm keeps an account of the number of requests allocated to each bucket (client) and then distributes the requests accordingly. Let us go through the algorithm with the help of the following figure:
Imagine having a bucket containing N tokens.
If a request arrives, we take one token out from a bucket and process the request.
Suppose there is no token left in the bucket, we discard and do not process the request.
At every fixed interval, we replenish the tokens in the bucket back to N.
The obvious question now is how is this actually implemented in a real world setting.
Imagine each bucket being mapped to a client.
A client can be uniquely identified by a signature (userId, IP, etc.).
Each token is a request.
With every processed request, the token count is decremented.
Based on the accepted rate of processing requests, the tokens are replenished every few hours.
Pros: Let us discuss the advantages of this approach.
The algorithm is easy to implement, understand and debug.
The algorithm is fast, and scalable.
Cons: Let us discuss the disadvantages of this approach.
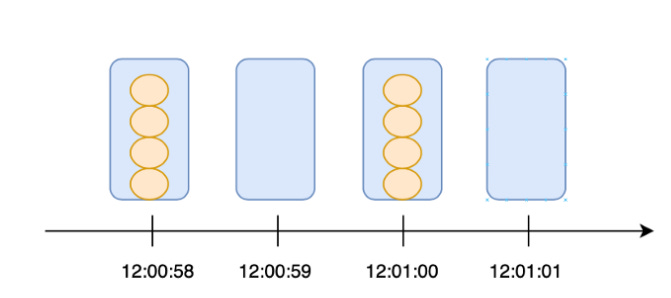
The algorithm may not be very accurate. Let us take the following scenario.
12:00:59: User triggers four requests.
12:01:00: We reset the tokens back to 4.
12:01:01: User triggers four requests again.
In this scenario, the user is able to trigger 8 requests within two seconds. However, this puts unnecessary load on the backend servers. To fix this problem, let us discuss some of the other approaches.
public class TokenBucket {
Leaky Bucket: One of the problems with the Token Bucket algorithm is that the user can trigger requests at the edges of the replenishing window (~ 15 seconds in the last example). The Leaky Bucket algorithm serves to fix this problem. To understand the leaky bucket algorithm, let us go through the following exercise:
Imagine a bucket with a leak. The leak drips at regular intervals.
When a request comes in, we fill the request into the bucket.
At every fixed interval, a request “leaks” out from the bottom and gets processed.
The leaky bucket follows the FIFO (First In First Out) concept and can be implemented using a queue. Using the leaky bucket, requests can come in at different rates while the server processes them at a constant and predictable rate. As the saying goes, “There are no best solutions, only trade-offs.” A consistent rate implies that the leaky bucket processes requests at an average rate leading to a slower response time.
Fixed Window: The fixed window algorithm is very similar to the token bucket algorithm. Here is a run-through of the algorithm:
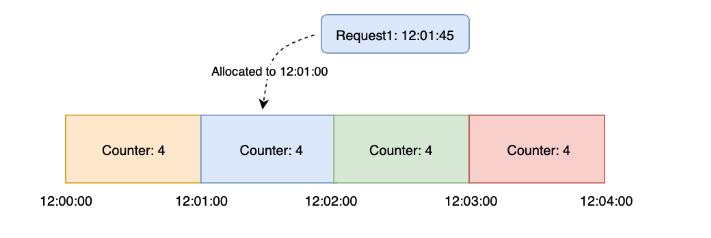
The timeline is split according to minutes for each window.
Each window contains a counter of 4.
When a request reaches, we allocate the request based on the FLOOR of the timestamp.
If the request comes in at 12:01:45, it will be allocated to the window of 12:01:00
If the counter is larger than 0, we decrement the counter and process the request.
Else, we discard the request.
As with token, the biggest drawback of the fixed window algorithm is the following:
It will potentially lead to a sudden burst of traffic near the boundary of the window.
If the counter runs out at the start of the window, all clients need to wait for a long reset window.
Difference with Token Bucket
One may ask the question as to what is the difference between token bucket and fixed window? (Link). To understand the difference, let us go through the following explanation:
Token bucket has two parameters as follows:
Bucket size: The maximum number of tokens that a bucket can hold.
Refill rate: The rate at which N tokens are added to the bucket. Let us say that this is 1/10 i.e. 1 token is added every 10 seconds. In this case, the user can trigger at max 2 requests within a short interval.
In the fixed window algorithm, all the tokens are added simultaneously at the edge of each window. This leads to a bigger burst at the edges than in Token Bucket if the refill rate is well adjusted.
Sliding Window: The sliding window algorithm is akin to a token bucket but solves the problem of handling traffic bursts. Let us assume that the allowed request rate is four requests/minute. Here is the algorithm:
An array is used to store the recently processed requests.
When a request is made, we loop through the array and check the number of requests processed within the last minute.
If the number of requests processed within the last minute is less than four, we add the request to the array and process it.
As we loop through the array, we pop up requests that are processed long before the last minute.
GIven that we process requests based on the concept of window, the rate limit is adhered to accurately i.e. only a predefined maximum number of requests are allowed through a predefined window.
Distributed Design
Let us assume that we have a web service with three different hosts. The service can handle a cumulative of 4 requests per client (as shown in the figure below). The first question to ask is how many tokens should be allocated to each bucket. In an ideal world, we should distribute 4/3 tokens to each bucket. However, that does not work in an actual world setting. The reason for this is that the load balancer distributes the requests across the hosts based on the load that the hosts have. The load can be randomly distributed based on how the input requests are distributed.
Let us assume the following distribution of requests:
Host 1 gets 2 requests
Host 2 gets 1 request
Host 3 gets 1 request
If a new request from the same client hits host 1, should the request be allowed or not? Ideally, NO as the client has already used up 4 requests. However, how does the server come to know about the distribution of requests? We will answer this in the next section.
Communication Algorithms
To solve the problem, we discussed above, we can use a Communication Algorithm, for the hosts to be able to talk to each other. There are several algorithms that we can use. Let us discuss each of the options.
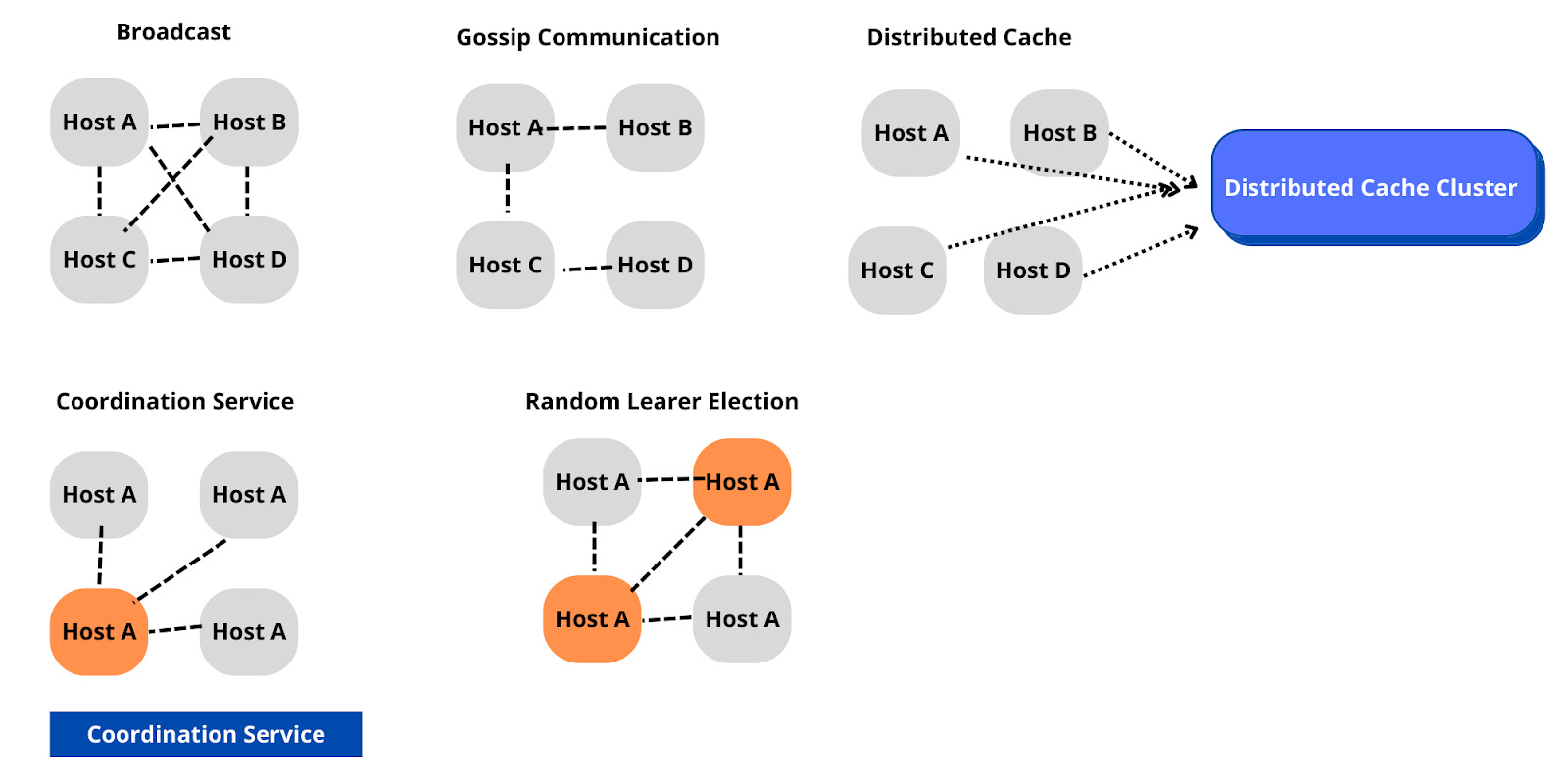
Option 1: All To All (also known as Broadcasting): In the mode of broadcasting, each of the nodes sends messages to every other node. The disadvantage of broadcasting is that it results in redundant messaging and heavy usage of network bandwidth. Pros: Ease of implementation.
Cons: Not scalable with the number of hosts.
Option 2: Gossip Communication: The gossip protocol is based on the same methodology as epidemics spread. Typically, nodes talk to peer nodes (sister nodes) in the network and the information spreads to all the nodes in the network.
Pros: Ease of implementation.
Cons: Not scalable with the number of hosts.
Option 3: Distributed Cache: Using a distributed cache is another mechanism with which we can have nodes communicate. In a distributed cache setting, the nodes talk to a central cache (Memcached, Redis, or DynamoDB) and store the updated state. While this protocol reduces the overhead in communication, it brings in a single point of failure i.e. the central cache.
Pros: Scalable design as the distributed cache cluster can scale independently of the host machines. Cons: Complexity of implementation of the cache. Reliance on the correctness of the cache’s implementation.
Option 4: Coordination Service: Another commonly used protocol is using a coordination service. The coordination service is a third-party service that helps elect one of the nodes as the leader. Each of the hosts talks to the leader and syncs information with the host. Typically, Paxos, and Raft are used to implement the Coordination Protocol. Zookeeper is a widely adopted service used to implement a Coordination Service.
Pros: Scalable design as the hosts can scale independent of the coordination service.
Cons: Complexity of implementation. Complexity in case of failure of the leader.
Option 5: Random Leader Selection: Instead of relying on a central coordination service we can go with a random algorithm to pick a leader. An example could be using the MAC or IP address and using the host with the largest address. Ideally, this should lead to a single leader being elected, and all the hosts talk through this leader. Even if there are multiple leaders that are elected, this should not result in any issues since the information will eventually converge to the right state of the cluster.
Using one of the aforementioned communication methodologies we can extend the design we started with a single node to a distributed rate limiter design.
This wraps up the overall discussion of the problem. I hope you found the discussion helpful.
Regards, Ravi.
Thanks for reading Ravi's System Design Newsletter! Subscribe for free to receive new posts and support my work.