Interview Preparation: Designing An Auto-Complete Engine From Scratch
How Do We Design Search Engines From Scratch

Hello there 👋 ! We are growing fast and are now at 200+ subscribers 💪 💪. Thank you for your love and support ❤️ ❤️. I am enjoying it, I hope you are enjoying it too!
As a part of this newsletter, I will curate a list of questions that will help you prepare for interviews, apart from focussing on fundamental ideas. I will keep them under the “Interview Preparation” tag and share these regularly. Let’s start with my favorite - designing a large-scale auto-complete engine.

Functional Requirements
The system should be able to satisfy the following functional requirements:
Search for strings from a collection of predefined strings.
Provide completions from the set of strings indexed. The type of matches we will need are prefix matches only.
To understand the requirement, let’s assume that you have a set of all the cities listed. Let’s assume that you are building a travel application, and so you need to return to the cities that are traveled to most often. Here is a list:
London, England.
Paris, France.
New York City, United States.
Moscow, Russia.
Dubai, United Arab Emirates.
Tokyo, Japan.
Singapore.
Los Angeles, United States.
Barcelona, Spain.
Madrid, Spain.
Now let’s say the user types in the letter, D. The engine should suggest the following:
Dubai,
Delhi,
Damascus
.....
Note: This list is ranked in order of its popularity.
If the user types in Dubai, the engine should recognize that it is the city of Dubai.
Non-Functional Requirements
Latency: The engine should return results within 10 ms.
Scalability: The engine should be able to index 10 Billion strings.
Throughput: The engine should support a QPS of 1000 requests/hour.
Availability: The engine should experience zero downtime.
Customizability: The engine should be customizable.
Memory + Disk Availability: We can assume an infinite amount of memory and disk available.
System Metrics Every Engineer Should Know
Before we begin solving the problem, it is essential to understand the most common system metrics. These are as follows:
L1 Cache Reference: 0.5 ns
Latency of access to main memory: 100 ns
Latency of access to a solid-state drive: 100 us
Latency of access to hard disk: 10 ms
Round trip within the same data center: 500 us
Maximum memory in 1 web server: 256 GB
Data Structure Design
Let’s first start with the design of the data structure for the search index. Typically, there are the following two different data structures that one can use for searching information:
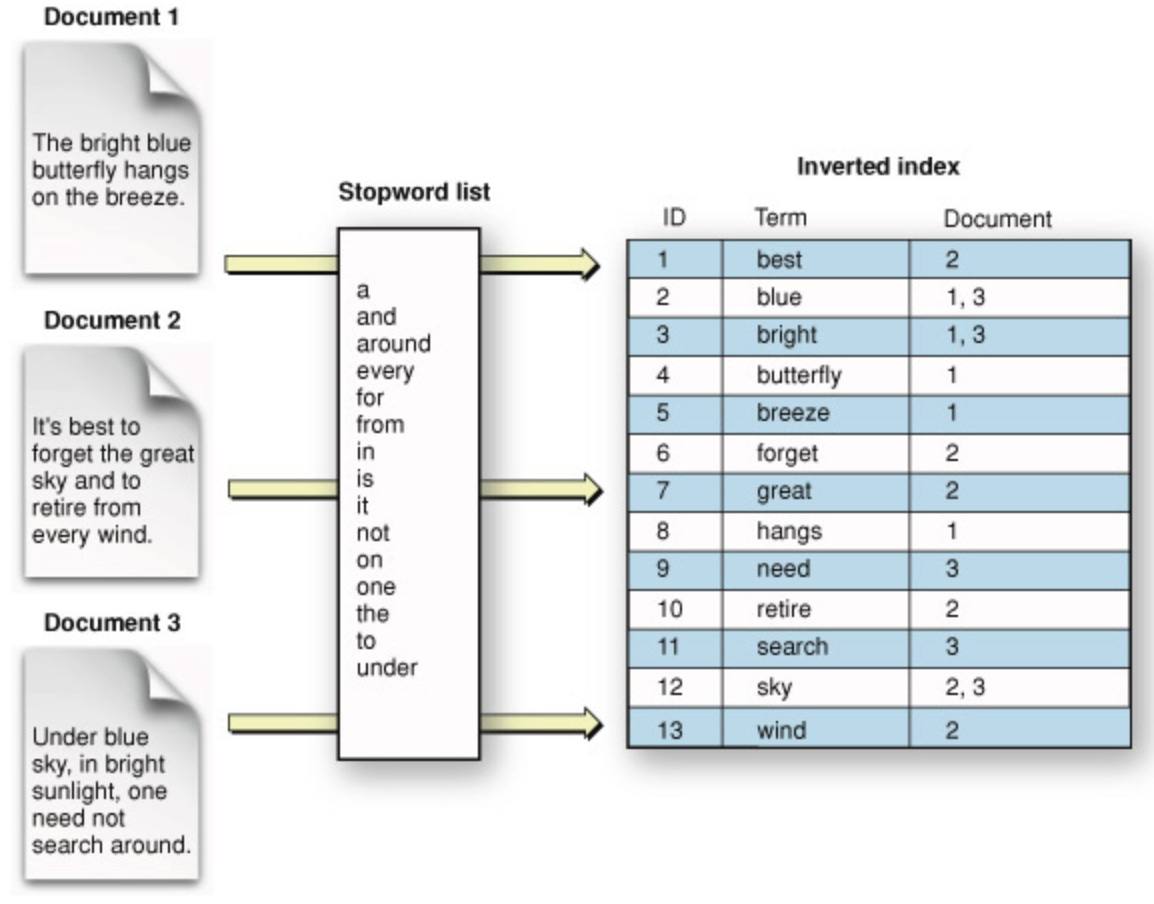
Inverted Index: Inverted Index, also known as the postings list or inverted file, is an index storing scheme mapping content, such as words or numbers, to its location in a table. Let’s take the following example. In the image below, we can see a list of words derived from their respective documents. Each word (also called a term) has an associated ID and the Document number associated with it.
While Inverted Indices are good for searching complete terms, they are not amenable to prefix, suffix matches, etc.
Binary Search Tree: A Binary Search Tree is a well-understood data structure. It has the following properties:
Each node has two children.
The left subtree of a node contains only nodes with keys lesser than the node’s key.
The right subtree of a node contains only nodes with keys greater than the node’s key.
The comparison can be defined using lexicographic comparison for strings.
The search complexity in a well-balanced binary search tree will be M * log N, where M is the length of the longest string and N is the number of keys in the tree.
Trie: A Trie is an efficient information retrieval data structure. Tries are built on top of the same idea as a tree but are optimized for storing information for faster retrieval. The search complexity can be brought down to the optimal limit (i.e., key size). A trie makes a trade-off on the time-complexity (i.e., reduces the time-complexity) but requires a higher amount of space (increases the space-complexity).
When comparing the data structures, tree-like data structures support prefixes and exact search semantics much better than a Hash-Table. When we reach a tree with a trie, a trie becomes efficient in terms of time complexity.
We, therefore, will go a trie-like data structure.
Memory vs. On Disk Structure
Regarding the system design, the next question to answer is whether we should keep this data structure all in-memory vs. keep it on disk vs. memory.
Let’s do the following calculations to understand this better:
Memory Requirements
Let’s assume that each node represents a city. A city will have some metadata associated with it. It may be the city’s name, synonyms, country, geo-location, population, popularity, etc. Let’s assume that we have 100 Bytes of data. Considering 10 Billion strings, this would come out to be 1 TB data. We can safely assume that we cannot keep this in a single off-the-shelf web server. We are assuming that a typical off-the-shelf web server has 256 GB of memory capacity.
Data Layout
All Data On Disk: In this design, we will assume that all the data is on disk (for argument’s sake). Let’s assume that a typical access pattern would look like at least two different disk seeks. I am assuming that we are retrieving ten results. And, optimistically, they are spread over two separate pages. This would generally take 20 ms if the pages are not in the memory buffer and are non-contiguous. In general, the tail-latency would be high if the disk seeks to follow a very random pattern. Given our requirement of 10 ms lookup latency, this seems like a No-Go.
Data In Hybrid Store: This design assumes that 20% of the data is kept in memory, and 80% resides on a disk. Considering that most of the hot data (i.e., frequently accessed) can be cached in memory, this technique can be cost-efficient and perform better. The tail latencies will still involve access to the disk, which may incur 10+ ms of access latencies.
All The Data In Memory: In this design, we will assume that all the data is in-memory. The cost of access will be low, i.e., 10 - 100 ns per memory reference. The bottleneck, therefore, shifts away from data access to compute (< 10ms). Given that we have an infinite amount of memory available (we will discuss how to achieve this), we should keep all the data in memory.
Data Structure Design
Let’s now design the core data structure as follows:
struct NonLeafNode {
vector<Node *> children;
String value;
};
struct LeafNode {
vector<Node *> children;
String value;
// Metadata
double popularity;
String country;
double population;
..........
};System Architecture
Scalability
Let’s next discuss how the system should scale. For the application to scale to 1 TB of in-memory, we need to support scalability. The approach we will take is horizontal scaling over vertical scaling (Read more about scaling here).
Vertical Scaling:
Pros:
Ease of implementation.
Cons:
Limitation on the scale.
Hardware becomes complex and expensive as the size increases.
Horizontal Scaling:
Pros:
Provides infinite scaling (through elasticity).
Provides more fault tolerance (through redundancy).
Cheaper (can be implemented with off-the-shelf hardware).
No need to rely on complex, specialized hardware.
Cons:
Introduce the complexity of implementation.
With horizontal scaling, we will divide the data into multiple servers. Let’s assume that we need to store 1 TB of data and each server has 256 GB of memory. Assume that the overhead of trie is 50%. We need nearly 2 TB of memory. This amounts to 8 web servers.
Sharding
To divide the data between the eight nodes, we will go with sharding (Read more about sharding here). There are several ways to shard the data. We will discuss the pros and cons of each in the following section:
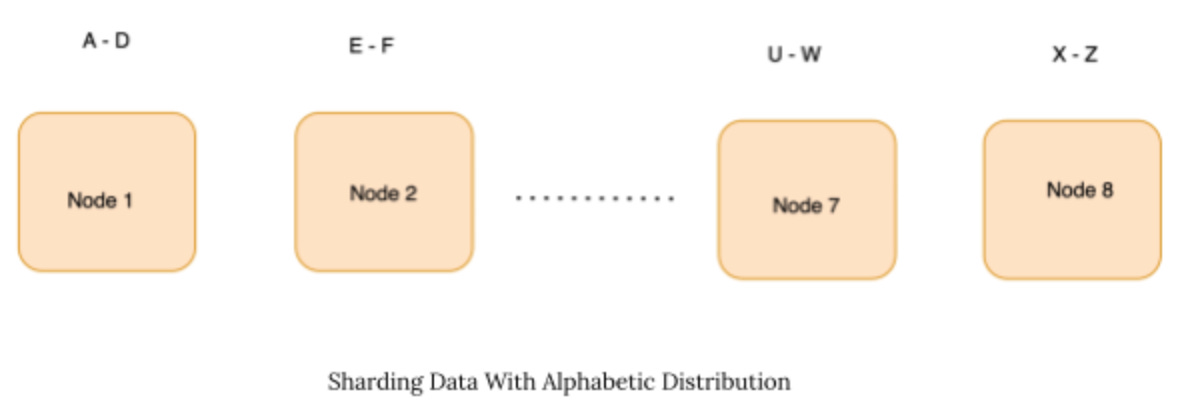
Sharding the data alphabetically: The most basic scheme we can use is sharding the data using an alphabetic scheme. The diagram below shows the distribution of data, sharded across the nodes. The advantage of this scheme is its simplicity of implementation. The drawback of this scheme is that it can cause excessive pressure on specific nodes. The nodes that hold data with A, R, or S will have many strings indexed. This is due to a skew of data distribution in the English language.
Sharding the data randomly: In this approach, we uniformly sample each node and store the data using a method similar to random trees. The main idea is to distribute the data randomly (using a pre-defined hash function) and ensure that the load is evenly distributed. Even though the load remains evenly distributed, there are certain drawbacks to this approach. In case of a server failure, all the data needs to be re-distributed, which can cause upstream disruption.
Sharding the data using Consistent Hashing: Consistent hashing (blog, paper) is a technique that uses the idea of distribution using random trees but takes a slightly different approach concerning data distribution. Like other hashing schemes, consistent hashing assigns a set of items to buckets so that each bin receives roughly the same number of items. Unlike standard hashing schemes, though, a small change in buckets gives only a slight change in the assignment of items to buckets. Consistent hashing achieves this by building “ranged hash functions.” A ranged hash function ensures smooth distribution, a low spread of keys, and a low load on each bucket. (Note: We will cover the intuition behind consistent hashing in a different blog).
Consistent Hashing is the most robust and performant scheme among the schemes mentioned here and is used commonly.
Availability
One of the problems with keeping all the memory is that a part of the data may become unavailable for a significant period if the server goes down. This is because reading the data from the data source (from the disk) and building the index in memory is a slow process. The user will not access the part of the data that is currently not in memory.
Introducing Redudandancy In the Design
To ensure high availability, we introduce redundancy in the system. Each shard is now present on two different nodes rather than on a single node.
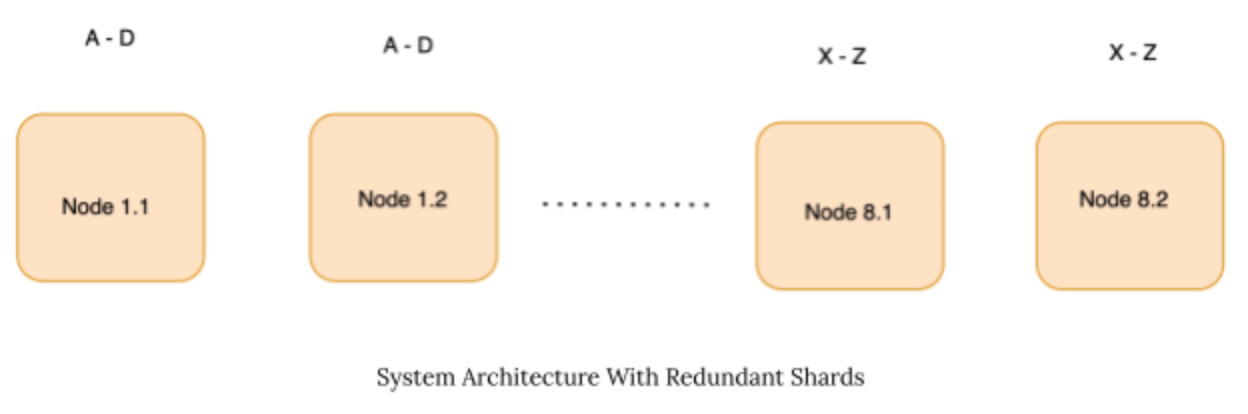
Let’s look at the image above. We can see that each shard (e.g., A-D, X- Z) is now present on two nodes instead of one.
Pros:
This design ensures that even if one of the shards is unavailable, the other shard can serve the requests.
In case of high pressure on one node, requests can be redirected to the same shard.
Cons:
This increases the memory requirement of the system.
This introduces extra complexity of implementation (shard-routing, synchronization of shard data, etc.).
High-Level Diagram And Data Flow
Here we discuss the high-level view of the search engine and the data flow diagram.
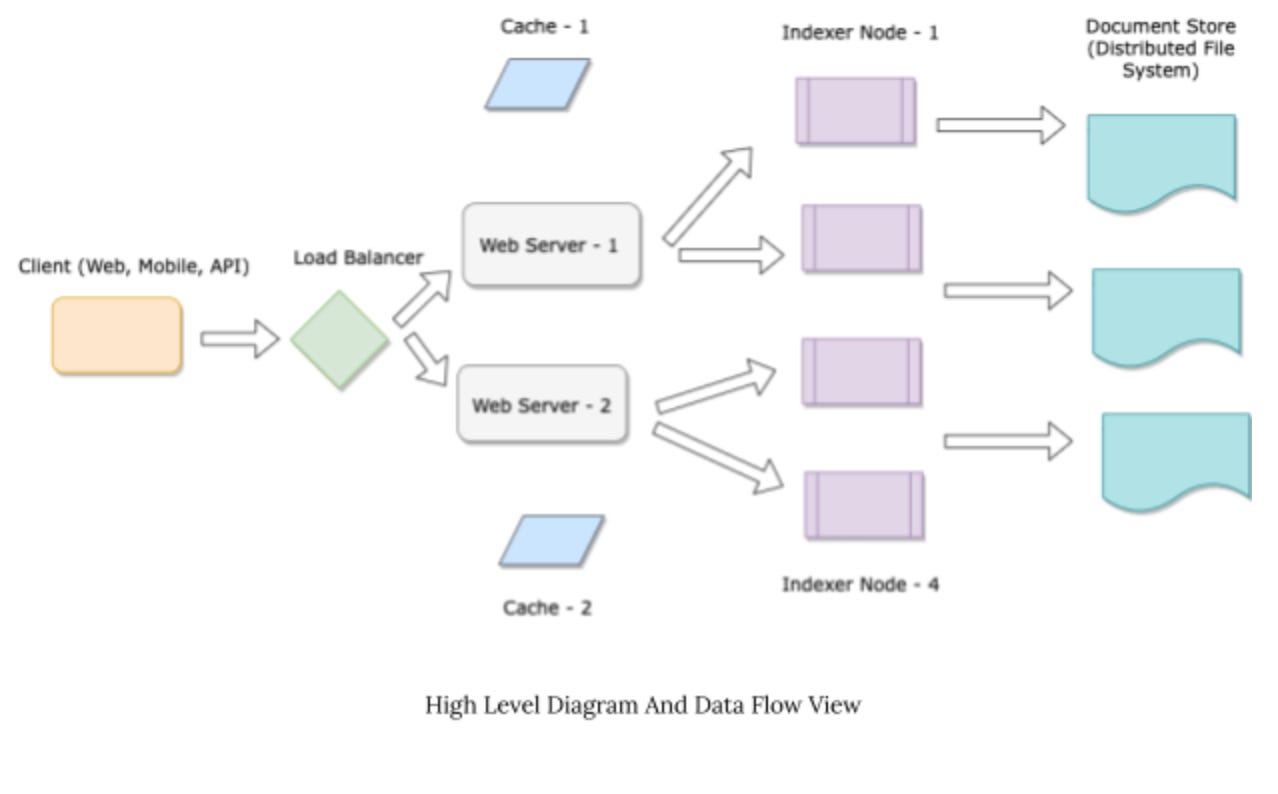
The major components of the system are as follows:
Client: The client consists of a Web App, Mobile App, or API end-point that hits the backend services.
Load Balancer: The load-balancer is used to route requests to the webserver and balance the load between the two services.
Web Server: The web servers encode the business logic. In the auto-complete engine, the web-server will do the following:
Validate the request.
Check with the caches if the results for the request are already cached. If not, hit the indexer nodes.
Find the indexer node on which the request should be routed.
Send a request to the correct set of nodes (using the Consistent Hashing Scheme).
If the request is for an exact match, then only one node needs to be looked up.
If the request is for a prefix match, one or two nodes may be looked up.
Aggregate the results from the indexer nodes, rank them by personalizing them to the user, and send the results back to the client.
Caches: The caches store intermediate results from the indexer nodes intermittently. We may have in-memory caches (such as Memcached) or support persistence on-disk caches (Redis).
Indexer Nodes: The indexer nodes store the distributed trie data structure. Our design would have 16 nodes that hold 1 TB of data (with a redundancy factor of 2). The Indexer Nodes are backed up with a distributed file store. If an indexer node goes down, the cluster manager (not shown in the figure) will restart the node. On a restart, the node will then re-index all the data from the distributed file store.
Distributed File Storage: Stores the actual data (i.e., 10 Billion strings). This may be built using Amazon’s S3.
For the scope of an interview, this is a good enough discussion to have with the interviewer. There are a few topics that need to be covered to complete the scope of the interview. These are as follows:
I. API Interface between the client and the web-server, and the web-server and the indexer-nodes.
II. Solving for challenges such as getting top 10 matches, auto-completion for empty strings, handling failover between nodes, etc.
We will cover a blog on advanced design for Search Engines where we will cover (I) and (II).
References
Database Sharding. Database sharding is the process of… | by Vivek Kumar Singh | System Design Blog
System Design: Challenges In Distributed Systems (Availability)
The System Design Masterclass
Click here for more course details | Subscribe To My Weekly Newsletter |
Find Me On LinkedIn | Drop Me A Message On Email |
Cheers,
Ravi.
Also, it would be good to discuss about the API Endpoints?
Could you give more info about what is the key to consistent hashing? How the trie is updated?