
Hello there 👋 ! We are growing fast and are now at 1600+ subscribers 💪 💪. Thank you for your love and support ❤️ ❤️. I am enjoying it, I hope you are enjoying it too!
A quick recap. In the last three newsletters, we looked at the lessons from Netflix’s notification service, the design of a scalable notification service, and the design of a scalable search engine. In this newsletter, I discuss the design of a distributed cache. I hope you enjoy reading this one. You can use this for your interview preparation.

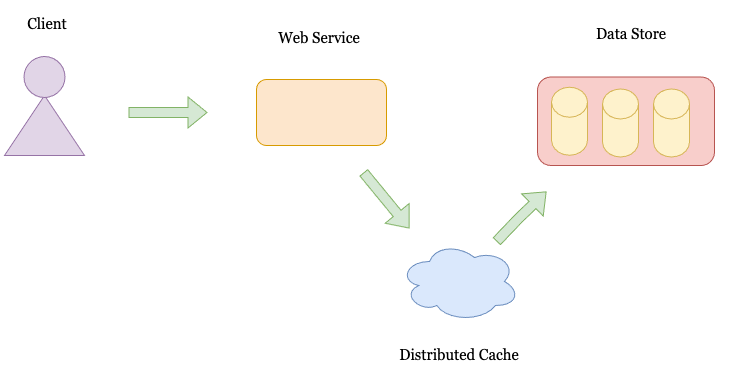
A Generic WebService Setup
Generally, a webservice has the following setup. There is a client that connects to a webservice. The client may be a web application, mobile application, or API client. The client then connects to a web service. The web service fetches the required data from an underlying data store. The data store may be a relational store (MySQL, Postgres SQL), a NoSQL store (Cassandra, MongoDB), or a file store like Amazon’s S3.
As the system scales, the performance of the data store (both in terms of latency and throughput) starts to degrade. The degradation can be because of a high number of requests, high parallelism, expensive queries, etc. To alleviate the problem, web services employ a cache to keep a pre-recorded set of queries. In general, applications have a Zipfian distribution pattern. 80% of the requests are served by 20% repeated queries. Therefore, Caches are a powerful element when scaling an application.
This blog discusses the design and implementation of caches in further detail.
Caching: Definition, Types & Use Cases
Cache: Definition
A cache is a short-term memory used to store data items from databases, servers, or other secondary storage layers. It is typically faster than the source and keeps data for a smaller period. Normally, a cache helps speed up the application, reduce the load on the backend servers, and help scale the system. A cache may sit on a single node or multiple nodes. For the course of this blog post, we will focus on the design and implementation of a distributed cache and discuss the advantages and challenges of maintaining one.
Distributed Caching
A distributed cache is a cache system that sits on several nodes (a) within a cluster, (b) across multiple nodes in different clusters, (c) across several data centers located in the world. Why do we not use a simple one-node cache? The answer to this is simple. As a system scales up, they need to store hundreds of GB of data in the cache. It becomes impossible to store that much amount of data in a single node’s memory. Therefore, the requirement of building a distributed cache becomes evident.
Why do we need distributed caching?
There are several advantages that a distributed caching system provides. Here are the requirements for a distributed caching system.
Functional Requirements
Put (key, value): The first requirement of a cache should support a put operation on a key-value pair. The value is mapped to the key and can be retrieved using the key uniquely.
Get (key) - The second requirement of a cache is that it should support a get operation. The get operation takes a key as the input parameter and emits out the value. In case the key is not present in the cache, the get operation returns null.
Furthermore, most caches also treat a Get, and Put as legitimate access to the item and maintain metrics around the access patterns. We will discuss this in detail in this blog post.
Non-Functional Requirements
✅ Scalability: The cache cluster should scale-out with an increasing number of requests and data. The constraint remains that the performance of the application shouldn’t degrade as the application scales 10x in the data it stores or the number of users using the application.
✅ Highly Performant: The gets and puts should be fast. This is the primary requirement of a cache cluster. The performance in terms of latency of look-ups shouldn’t degrade as the number of requests and data scales on the cluster.
✅ Highly Available: The cache cluster should service hardware and network failures. In case a node within the cluster fails, the cache cluster should remain alive and the requests should be served from other nodes. It should be noted that a lot of applications have a requirement of eventual consistency. Take an example of caching the likes on Facebook Photos. For a user, it may be fine for the application to show 100 likes instead of 110 likes. For such applications being available is a requirement from the cache clusters.
Use-Cases
Distributed caches have several use-cases. This section discusses some use-cases of a distributed cache.
Session Store
A cache server (such as Memcached, Redis) can be used to store information related to a user’s session. Webservices use the session information to authenticate access to each API by a user.
Database Caching
Databases store 100 GBs to terabytes of data. Access to data is expensive and induces a lot of load on the server that is running the database. To alleviate this load, caches are deployed as the first layer of access to a database to ensure that the data stores can scale up.
API Caching
Typical web servers can handle 10-100k QPS depending upon the complexity of the API being triggered. However, as the APIs become complex and the number of users increases, it gets hard to scale up webservers. Caches help alleviate this by caching responses to the most common and recent API accesses.
Local Cache
We will start with a local cache and then move to the design of a distributed cache.
Data Structure
Hash Table: A hash table is used to locate the position of the value within a doubly linked list.
Queue: A queue is used to maintain a list of all the items in the cache. It supports constant time for add, update, and delete operations. We use a doubly linked list and implement an LRU cache implementation.
Algorithm
Retrieval Algorithm
Step-I: Check if the item is in the cache.
Step-II: If the item is not in the cache, return null.
Step-III: If the item is in the cache, return the item and move the item to the head of the list.
Note:The item at the front of the list is the most recently used.
The item at the tail of the list is the least recently used.
Update Algorithm
Step-I: Check if the item is in the cache.
Step-II: If the item is in the cache, update the value of the key and bring it to the front of the queue.
Step-III: If the item is not in the cache, check if the hash table is at its capacity.
If the hash table is not at its capacity, add the item to the front of the queue.
If the hash table is at its capacity, evict one item (based on the eviction policy) and then insert the item to the front of the cache. The item is deleted from the tail of the list.
Eviction Policy
Least Recently Used: LRU is the most commonly used policy for cache eviction. Many applications have temporal locality while accessing items. Items that have been recently used have a higher probability of being accessed.
Least Frequently Used: LFU is a policy in which the frequency of access is maintained with each item. The underlying hypothesis is that items accessed more often have a higher probability of being accessed than those that are rarely accessed. Furthermore, the cost of a cache miss on a rarely used item is much lower.
FIFO (First In First Out): FIFO is the most straightforward policy that says that items that came into the cache earlier should be evicted earlier. The items that are old now (came in earlier) will have a lower probability of being accessed.
Elements of a Cache System
This section discusses some of the basic elements that make up a cache system They are as follows:
Cache Client
A cache client is a library that resides on the client-side. Typically, it knows about all the cache servers. It implements a search algorithm to identify which server should the request be routed to. The algorithm may be a simple hash-based search or may be somewhat more sophisticated, such as a binary search for implementing Consistent Hashing. We discuss Consistent Hashing subsequently in this blog post. It uses TCP or UDP protocol to talk to servers. If the server is not available the client assumes that it was a cache miss.
Cache Server
A Cache Server stores the data that the client requires from the cache. Typical caching servers are single nodes or distributed in nature. Some of the common cache servers are Varnish, Memcached, Redis, Amazon’s DAX for Dynamo DB, and ElasticCache. The cache server is also connected to the underlying data store to retrieve the data in case the data is not present in the cache.
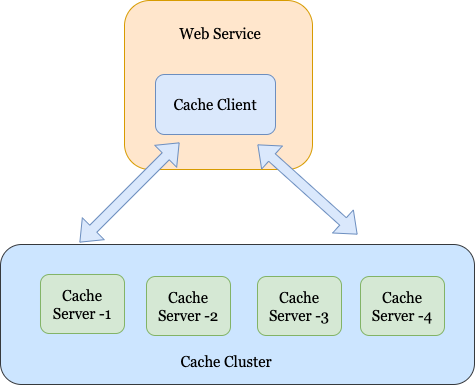
Designing A Distributed Cache
Co-Located vs. Remotely Hosted:
The cache server may be located on the same host as the WebServer or co-located with the Webserver. The tradeoffs for the two choices are as follows:
Advantages of co-located cache:
The co-located cache will scale as the web-service scales
Extra hardware and operational cost are low.
Co-location can help reduce lookup latency
Advantages of remote caches:
Isolation of resources between the web server and the cache. So, even if the machine on which the webserver is deployed goes down, the cache server still remains up.
Flexibility in choosing different hardware for the webserver and the cache server.
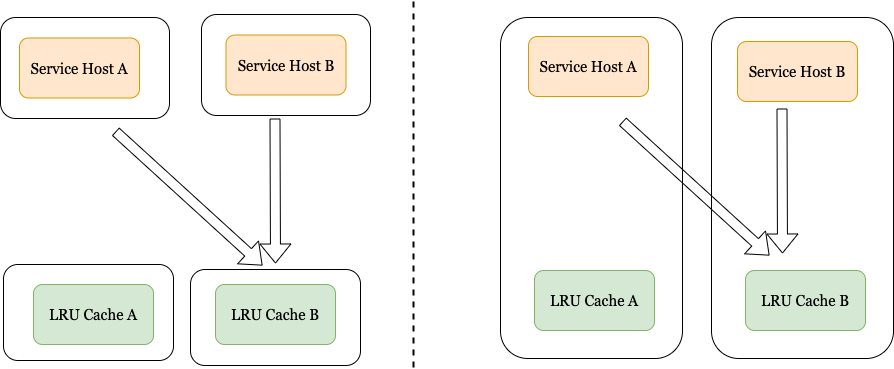
Hashing Algorithms
To deduce which bucket the item should be stored in the cache client needs to rely on a search algorithm. In this section, we will skim through two commonly used hashing techniques.
Mod-based hash: In this technique, the client maps the item using a simple mod-based function. An example of this could be as follows:
Server-id = f(item’s key) mod N
where the function f translates the item’s key into an integral space, and N is the number of servers in the system.
Tradeoffs
Advantages: It is a function that is easy to implement and understand
Disadvantages: The technique is not resilient to server failures. If a server goes down, all the keys will have to be re-hashed. It makes the overall approach sub-optimal.
Consistent Hashing
Consistent Hashing is a technique wherein the items are distributed amongst servers using a family of hash functions. The image below simplifies the hashing scheme. Each of the servers is hashed using a key. This can be using their IP address in a value space (which is circular). The items are hashed in the same space. All the values between two servers (say Server-1 and Server-2) go to one of the servers. For argument’s sake, let us assume that these values go to Server-1. Extending the design,, all the values that lie between Server-2 and Server-3 go to Server-2 and so on.
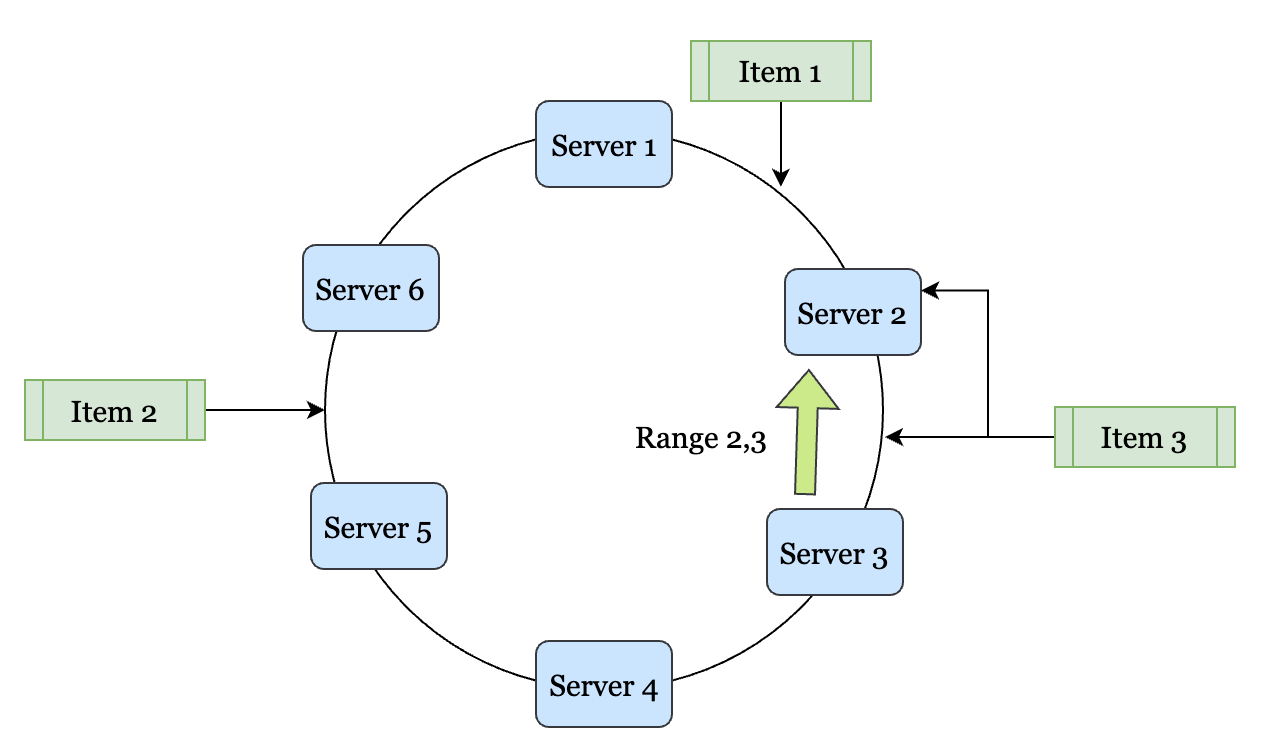
If Server-2 dies, all the keys that ownsServer-2 owns are then copied over and owned by Server-1. This way, all the other keys remain stable, and only two servers are distributed. The design is much more stable than using a Mod Function for the distribution of the keys. Consistent Hashing is therefore used much more heavily as compared to other hashing schemes.
Achieving High Performance
The LRU algorithm can fetch an item in O(1) time-complexity and is fast. ✅
Caches keep hot-keys in memory (Memcached, Redis) and lookups are fast. ✅
Consistent Hashing can find a node in (log N) time through a binary search. ✅
Cache client accesses data from the server using TCP, UDP. These protocols are fast. ✅
Achieving High Availability
What happens in the case when one of the cache servers goes down? The list of cache server hostnames and ports can be maintained in one of the following ways:
Single file on each cache client.
Single file on a shared storage server (E.g., in S3).
Accessible through a central configuration service such as ZooKeeper.

Trade-offs:
The disadvantage of maintaining the list in a single file is that the file needs to be manually updated and the server restarted in case of a server failure.
In order to avoid, web server restarts we can maintain the list of cache servers in a separate location within shared storage such as S3. The file needs to be updated manually, still.
The optimal approach is to maintain the servers in a configuration service such as Zookeeper and have the client use the configuration service to update the list of cache servers it can connect to for getting the cache data.
Achieving High Scalability + Availability
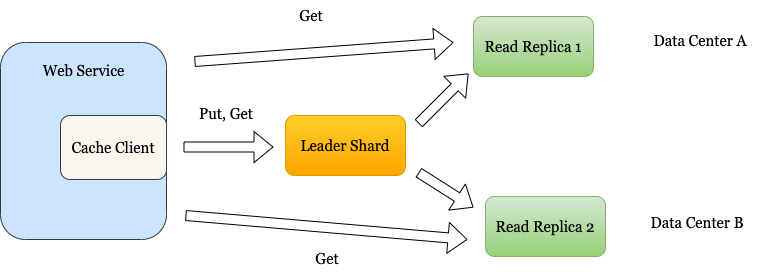
To ensure that the system scales and remains highly available, cache clusters take the approach of replication through data sharding. Sharding ensures that the data space is divided into many subspaces. Each subspace is then distributed to a different node in the cluster.
We can go with a master-slave replication model. Each shard has a leader and reads replicas. The writes go to the leader shard. The reads can go to either the leader or the read replica.
To deal with “hot shards”, more read replicas can be added to the cache cluster.
In case the leader shard goes down, a leader election process triggers. This can be done through a configuration service such as Zookeeper which assigns one of the replicas as the leader. The cache cluster remains available throughout the process.
References
Cheers,
Ravi.