

System Design: Challenges In Distributed Systems (Availability)
Designing For Higher Availability

Hello there 👋 First of all, I would like to thank all of you for supporting this newsletter. We now have over 150+ subscribers to this newsletter and are growing fast 🙌 🎉. Thank you for the love and appreciation ❤️. I would love to hear feedback from you. Topics that you would want to learn more from us.
Introduction
In the last two blogs, we deep-dived into the basic building blocks of a distributed system and the principles of Microservice Architecture. This blog will go through the common challenges that have to be considered while designing a distributed system. Specifically, we will focus on the CAP Theorem and discuss the availability of a distributed system.
CAP Theorem
The CAP (Consistency, Availability, and Partition Tolerance) theorem states that in networked shared-data systems or distributed systems, we can achieve two of three guarantees for a database: Consistency, Availability, and Partition Tolerance.
The CAP Theorem is also known as Brewer’s theorem and was introduced by the computer scientist Eric Brewer at the Symposium on Principles of Distributed Computing in 2000.
Consistency: Consistency means that all clients see the same data simultaneously (for strict consistency), no matter which node they connect to in a distributed system. For eventual consistency, the guarantees are a bit loose. Eventual consistency guarantees that clients will eventually see the same data on all the nodes at some point of time in the future.
Availability: Availability means that all non-failing nodes in a distributed system return a response for all read and write requests in a bounded (or reasonable) amount of time, even if one or more other nodes are down.
Partition Tolerance: Partition Tolerance means that the system continues to operate despite arbitrary message loss or failure in parts of the system. Distributed systems guaranteeing partition tolerance can gracefully recover from partitions once the partition heals.

Types Of NoSQL Database Systems
With the above theorem, we can classify the systems into the following three categories:
CA Database: A CA database delivers consistency and availability across all the nodes. It can’t do this if there is a partition between any two nodes in the system and therefore doesn’t support partition tolerance. RDBMS are good examples of these databases.
CP Database: A CP database delivers consistency and partition tolerance at the expense of availability. When a partition occurs between two nodes, the system shuts down the non-available node (i.e., makes it unavailable) until the partition is resolved. Some of the examples of these databases are MongoDB, HBase, and Redis.
AP Database: An AP database delivers availability and partition tolerance at the expense of consistency. When a partition occurs, all nodes remain available, but those at the wrong end of a partition might return an older version of data than others. (When the partition is resolved, the AP databases typically resync the nodes to repair all the inconsistencies in the system). Some of the examples of these databases are CouchDB, Cassandra, and DynamoDB, etc.
Note: As a part of this course, we will discuss these technologies in detail in the subsequent blogs.
Proof Of The Cap Theorem
Let’s look at a simple proof of the Cap Theorem using the diagram below.
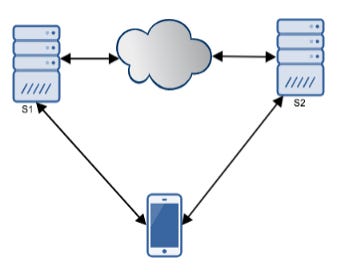
In the figure above, we have a straightforward distributed system where S1 and S2 are two servers. The two servers can talk to each other. Let’s start with the assumption that the system is partition tolerant. We will prove that that system can be either consistent or available.
Suppose there is a network failure and S1 and S2 cannot talk to each other. Now assume that the client makes a write to S1. The client then sends a read to S2. Given S1 and S2 cannot talk, they have a different view of the data. If the system has to remain consistent, it must deny the request and thus give up on availability. If the system is available, then the system has to give up on consistency.
This proves the CAP theorem.
Addendum: Spanner, Google's highly available global-scale distributed database, seemingly achieves consistency, availability despite being a globally distributed database. We will discuss how it achieves the impossible in a follow-up blog.
Availability
The availability of a distributed system is usually defined as the ratio of the total time that the system is up (i.e., can serve requests from the client within a bounded time) to the overall running time of the system. For example, Amazon’s S3 system guarantees an availability SLA of 99.99% over a given year.
Why is availability critical for businesses?
Due to a recent outage to Facebook services (Facebook App, Messenger App, and WhatsApp), Facebook lost an estimated USD 100 million. Last year, an outage in AWS took down a good chunk of the internet and caused many websites to be non-functional for a few hours. According to Gartner, companies lose an average of $336,000 per hour of downtime, with top e-commerce sites risking up to $13 million in lost sales per hour of downtime.
For any application to work well, they must remain available during their lifetime (esp. during peak hours). If the services go down, the users may experience high latencies, service disruption, or even data inconsistencies (if the application is PA). It can be severely detrimental to the users.
How is system availability measured?
This section discusses the three techniques that are used to measure the availability of a distributed system.
Time-Based
The most common measure of system availability is Time Based. In their book, Service Availability: Principles and Practice, Toeroe and Tam defines service availability as
Availability = MTTF / (MTTF + MTTR)
where MTTF is Mean Time To Failure and MTTR is Mean Time To Recovery. The Mean Time To Failure is the average time between the end of one outage and the start of another. Mean Time To Recovery is the average time taken to recover from outages.
Request Count Based
Count-based measurements use the success ratio of the received requests. The definition of availability can thus be measured as:
Availability = number of successful requests / number of total requests
The downside with this approach is that it is prone to bias. Power users tend to be 1000x active than the least active users and thus are 1000x more represented by this metric. So, if the system is being actively used by its power users, it will seem to be much more available than when it is not being used. It seems incorrect. Furthermore, it doesn’t capture the change in availability appropriately. Let’s say a system is up 3 hours and down for 3 hours. There will be many more requests during the 3 hours (when it is available) than during the 3 hours when it was down. It brings in misrepresentation and bias.
User Uptime
In their paper, Meaningful Availability, Google came up with a new user metric, user-uptime, as follows:

Here are the definitions for the terms used in the abovementioned formula:
uptime(u): Defines the cumulative time for which the system was up for all users.
downtime(u): Defines the cumulative time for which the system was down for all users.
It is a very conservative metric, where we consider any request that fails as contributing to the downtime even if the user doesn’t perceive it. Let’s take a concrete example to understand this better. For instance, while uploading an attachment to an email, the initial request might have failed. But an automatic retry done by the system may have succeeded. So the user may not even have noticed the downtime. The paper suggests that those few milliseconds when a request fails should still be considered as downtime.
Techniques For Availability
In this section, we discuss some of the techniques used to improve a system’s availability. These are as follows:
Redundancy
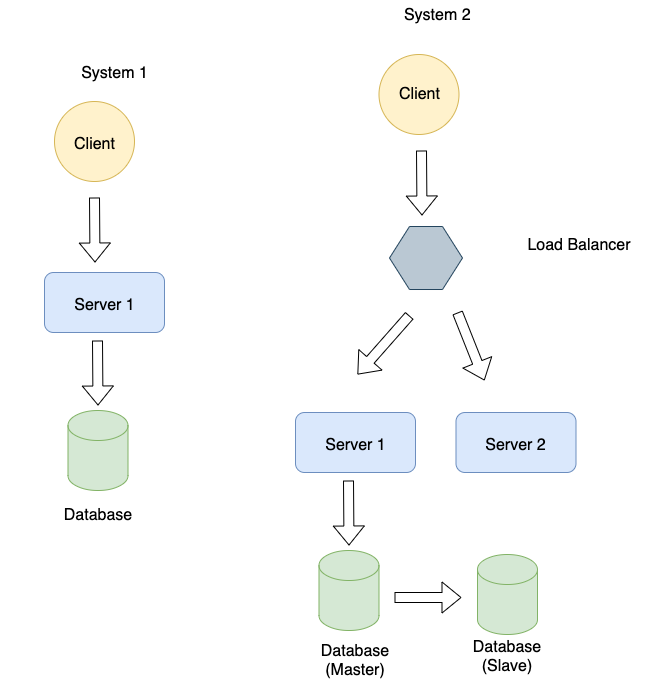
One of the most common techniques to improve a system’s availability is to introduce redundancy. Redundancy involves adding multiple copies of the same subsystem into the architecture. Statelessness and load-balancing are often employed to make redundancy work well for the availability and scalability of the system. Let’s take an example to explain this better. Consider the following scenarios. System 1 has a single client, a backend server connected to a single database replica. System 2 has a client, a load-balancer, two backend servers, and a master-slave replica.
The question then becomes which system is better. If we think about it, System-1 has multiple points of failure. Both the server and the Database engine can fail and make the system unavailable. On the other hand, System-2 can handle multiple failures. If server 1 fails, then server-2 can respond to the incoming requests. Similar is the case with the database engine. If the master fails, then the slave can handle requests from the upstream service. This makes System-2 much more robust than System-1.
Monitoring
Besides improving the service through redundancy, monitoring is another technique used to ensure that services remain available. In this post, we will use the term “Observability” interchangeably with Monitoring. In general, there are three layers on which monitoring is done. These are network, machine, and application. The most critical layer includes application metrics. It is the hardest as well.
Four Pillars Of Observability
There are four pillars of the Observability Engineering team’s charter:
Monitoring
Alerting/Visualization
Distributed systems tracing infrastructure
Log aggregations/analytics
I will wrap up this week’s newsletter at this point. We will cover other challenges (including monitoring for availability) in the following newsletter.
References
CAP Theorem and NoSQL Databases. What is the CAP theorem? | by Barmanand Kumar
CAP Theorem. CAP theorem also known as Brewer's… | by Vivek Kumar Singh | System Design Blog
Facebook outage: Lost ad revenue, advertisers could seek refunds
Measuring Availability of a Service, Meaningfully | by Mahendra Kariya
Monitoring and Observability. During lunch with a few friends in late… | by Cindy Sridharan | Medium
The System Design Masterclass
Click here for more course details | Subscribe To My Weekly Newsletter |
Find Me On LinkedIn | Drop Me A Message On Email |
thanks for the fantastic post! I find the following techniques as key takeaways to achieve high availability:
- eliminate single points of failure
- enable reliable failover
- detect failures proactively